
毎月、毎週など、定期的に同じようなデータファイルの処理をする ようなことはしていませんか?
このような作業で良くある悩みは次のようなものだと思います。
- 毎回同じような データのコピー&ペースト、セルの関数入力 が面倒
- 編集操作を間違えて 集計ミス が発生
- データが増えて ファイルが重くなってきた
こんな方には朗報です。Power Query のフォルダ内のデータを一括で取得する機能 を使えば、この問題は一気に解決ができます。
この記事では、Power Query による フォルダ内のデータ取得の基本から応用まで を解説します。
身近な Excel でできる業務効率化。しかも、基本の処理はほとんどがマウス操作でできてしまいますので、やらない手はありません。
皆さんも是非挑戦してみて下さい。
では、早速いってみましょう!
基本手順:フォルダから複数ファイルをまとめて読み込む
事前準備:フォルダにファイルを集める
この機能は 「形式が決まったファイル」 が1つ以上あることが前提です。
ファイルはまずは1つでも構いませんが、これをどこか決めたフォルダに保管してください。
はい、事前準備はこれだけです!簡単ですね。
では、このフォルダをからデータを取得していきましょう。
基本の操作手順
まず Excel のメニューから操作します。

ファイル選択ウィンドウが出るので準備したフォルダを選択します。

フォルダのデータを読み込んだ後の処置を選びます。

各ファイルのどの部分のデータを読み込むかを選択します。

複数ファイル処理の仕組み
このフォルダからのデータ取得する機能の最大のメリットは、ファイルが何個あっても Power Query が自動で処理してくれるので、膨大な手作業が一気に無くなることです。
この複数ファイルの処理の仕組みを理解しておくことで、応用的な使い方ができるようになりますので、ここで解説させていただきます。
複数ファイル処理の流れ
Power Query が内部で複数ファイル処理をしている流れは次のようになっています。

ファイルが何個あっても、ファイルに対して 同じデータ処理を繰り返し実行 してくれるところがポイントになっています。
人にとって、繰り返しの作業は大きな負担ですが、コンピュータは繰り返しの処理は非常に得意 です。
この繰り返し処理する部分が ヘルパークエリ です。
自動作成されるヘルパークエリの役割
基本手順でクエリを作成すると、図のように 自動的にヘルパークエリ が作成されているのが分かると思います。

それぞれのヘルパークエリの役割は図のようになっています。

「ファイルの変換」クエリ は Power Query が自動で更新してくれます。
ファイルごとの変換処理を変更したい場合 は、図の左に載せた3つのクエリを編集します。
それぞれについて解説します。
「サンプルファイルの変換」クエリ
このクエリがヘルパークエリの中で ユーザーにとって最も重要なクエリ です。
このクエリは通常の Power Query のクエリ編集と同じように、ファイル内のデータ処理を記録します。
次のような データ結合後にできない処理 をします。
- ファイルごとに含まれる 冒頭の不要なデータ行 を削除
- ピボットされた項目がファイルごとに異なる ものをピボット解除
この内容を工夫することで、より柔軟な複数ファイルの処理の自動化が実現できます。
全てのファイルに対してこの処理が実行されるので、処理するファイルは基本的に同じ構成 になっている必要があります。
次のルールを守ってファイルを作成します。
- データ範囲 を処理するケース ⇒ 同じ名前のシート、同じ列の構成
- テーブル を処理するケース ⇒ 同じ名前のテーブル、同じ列の構成
「サンプルファイル」クエリ
これは、「サンプルファイルの変換」クエリが どのファイルを参照するか を定義するクエリです。
デフォルトではファイル一覧の 最初のファイル になっています。
ファイル一覧の最初のファイルが毎回変わってしまいエラー発生の原因となってしまうような場合は、これを以下のように編集してサンプルファイルを固定化してみましょう。デフォルトのプログラムを図のように変更します。

変更後のプログラムでは、3行目で “SampleFile.xlsx” というファイルをサンプルファイルに指定しています。
これによりサンプルとして読み込むファイルを固定化することができます。
「パラメータ1」クエリ
このクエリはサンプルファイルの種類などを設定していますが、最初に自動生成された内容から特に変更することはありません。
不要なファイルを除外する方法
フォルダ内にデータ処理対象外のファイルがあると、エラーで処理が止まったり、処理結果がおかしくなったりしてしまいます。
不要なファイルの例
- 記入用のテンプレートファイル
- バックアップ用の一時ファイル
- その他の関係の無いファイル
このようなエラーを回避するための対策をご紹介します。
【対策】データのファイル名のルールを決める
読み取るべきファイルの名前にルールを決めておくことで、それ以外の名前のファイルは読み取らないよう設定ができます。
例えば、売上のデータであれば、ファイル名は “売上データ_2024-12.xlsx” というように、“売上データ” ではじまる ように決めておくことで、それ以外のファイルは処理から除外することができます。
この設定は次の手順で行います。
Power Query エディターでクエリを開く
この設定は、まず一通り基本の操作手順でデータ取得のクエリを作成した後に行います。
まず、以下の手順で本体クエリを Power Query エディター で開きます。
- Excel のメニューから データ > クエリと接続 をクリック
- ウィンドウの右にサブウィンドウが開くので、「その他のクエリ」の下にあるクエリ名 をダブルクリック
クエリを編集
続いてPower Query エディターの右にある「適用したステップ」の 一番上の「ソース」を選択 します。
すると図のような状態になると思います。このサンプルのケースでは以下の不要なファイルが読み込まれていることが分かります。

不要なファイルは次のようなものです。
- 他の誰かがファイルを開いていて、ファイル名が “~$” で始まる 一時ファイル
- テンプレートのファイル “テンプレート_売上データ.xltx” (拡張子が xltx)
これらをファイル名でフィルターをかければ良い訳です。
図のようにファイル名の列の フィルターのボタン をクリックして、テキスト フィルター > 指定の値で始まる を選択します。

ステップの挿入の確認ダイアログが出るので「挿入」ボタンを押して、このフィルターの手順(ステップ)を挿入します。

行のフィルター のウィンドウが開くので、図のようにファイル名の最初に来る「売上データ」を入力して OK ボタンを押します。

すると、図のように余計なファイルは除かれたファイル一覧になりました。

以上でクエリの編集は完了です。Power Query エディターを閉じます、閉じる際には図のように変更の保持を確認されるので、「保持」を押して閉じます。

更新日時で取得するファイルを絞り込む
例えば1ヶ月以内に更新されたファイルだけ処理したい場合は、Power Query エディターの詳細エディターで次のように編集します。

解説
- Table.SelectRows関数 でフィルターを適用します。
- [Date modified] 列(更新日時) の列でフィルターをかけます。
- DateTime.LocalNow()関数 で現在日時を取得し、更に Date.AddMonth関数 で1ヶ月前に変更します。
- 次の行の処理対象を、元の「ソース」から「フィルター」に変更します。
ファイルサイズなどの属性で絞り込む
更新日時以外にも ファイル属性 を使って絞り込むことも可能です。
フォルダを読み込んだ直後はファイル属性が展開されていない状態なので、まずファイル属性を展開します。
ファイル属性を展開
図のようにしてファイル属性を展開します。

- ② の部分で展開したい属性を選択します。ファイルサイズの場合は Size を選択します
- 「元の列名をプレフィックスとして使用します」のチェックボックスを入れておくと、列名が Attributes.Size と長くなります。これが不要ならチェックを外します。この場合は列名は Size となります。
属性を展開すると属性の列が表示されるので、属性の値でフィルターをかけます。
ファイル属性でフィルターをかける
例えば、小さすぎるファイル(1Kバイト以下)を除外するには図のように操作します。


サブフォルダのファイルを除外する
基本操作でフォルダの読み込みを行うと、下位のサブフォルダのファイルも 全て読み込みます。
例えば処理はしないけど、バックアップとして取っておきたいファイルをサブフォルダに保管しているような場合、このままでは不要なファイルまで処理することになってしまいます。
このような場合は、M関数式を以下のように編集します。

let
ソース0 = Folder.Contents("C:\PowerQuery_Sample"),
ソース = Table.SelectRows(ソース0, each [Attributes][Kind] = "File")解説
デフォルトで使われる Folder.Files関数 はサブフォルダまで読み込んでしまいますので、代わりに Folder.Contents関数 を使います。
Folder.Contents関数 はフォルダも取得してしまうので、ファイル属性の Kind が File に絞りこむことでファイルのみを取得することができます。
このように冒頭の2行を変更するだけで、無用なサブフォルダに保管されたファイルを処理の対象から除外することができます。
複数条件を組み合わせる
ここまで紹介したフィルターの条件を複数組み合わせてファイルを絞り込むことも可能です。
M関数の処理では一気に絞りこむのではなく、絞り込みを順番に適用 していきます。
サンプルプログラムは次のようになります。
let
ソース = Folder.Files("C:\PowerQuery_Sample"),
フィルターされた行 = Table.SelectRows(ソース, each Text.StartsWith([Name], "売上データ")),
フィルター1 = Table.SelectRows(フィルターされた行, each [Date modified] >= Date.AddMonths(DateTime.LocalNow(), -1)),
#"展開された Attributes1" = Table.ExpandRecordColumn(フィルター1, "Attributes", {"Size"}, {"Size"}),
フィルター2 = Table.SelectRows(#"展開された Attributes1", each [Size] > 1000)- 3行目: ファイル名 が「売上データから始まる」条件で絞り込み
- 4行目: 更新日時 が「1ヶ月以内」の条件で絞り込み
- 5行目: ファイル属性からファイルサイズ(Size)を展開
- 6行目: ファイルサイズ が 「1 K bytes 以上のもの」の条件で絞り込み
このように様々なパラメータでファイルを絞り込むことで不要なファイルを除外してエラーを回避することが可能です。
ここでご紹介したテクニックは不要ファイルの除外以外にも活用できますので、皆さんのニーズに合わせて活用してみてください。
フォルダパス変更に柔軟に対応する方法
基本手順でクエリ作成した後でフォルダパスを変えたい場合は、Power Query エディター でクエリを編集する必要があります。
同じ処理を複数のフォルダで切り替えて処理したいなど、頻繁に変更したい場合は少々不便 です。
この対策として、フォルダパスをセルに入力 して対応するという方法がありますので紹介します。
フォルダパスを入力するセルに名前をつける
フォルダパスを入力するセルを決めて、そのセルに例えば「フォルダパス」と名前をつけます。
- セルを選択
- セルのアドレスが表示されている 名前ボックス に「フォルダパス」と上書きしてエンターキー を押す
本体クエリを編集する
基本手順で作成された本体クエリを Power Query エディター で開いて、さらに「詳細エディター」を開いて M関数 プログラム を確認します。
プログラムの冒頭にフォルダパスが記載されています。このままではパスを動的に変更できません。
let
ソース = Folder.Files("C:\PowerQuery_Sample"),最初に「フォルダパス」と名前をつけたセルから値を取得して、その値を読み込むフォルダとして指定するようにコードを修正します。
let
フォルダパス = Excel.CurrentWorkbook () {[Name = "フォルダパス"]} [Content] {0} [Column1],
ソース = Folder.Files(フォルダパス),たった2行だけの修正ですが、これで Power Query を実行するたびにセルに書き込まれたフォルダからデータを読み取るようになります。
複数のフォルダを切り替えて処理するとか、管理の都合でフォルダの位置を変更する場合など、活用できます。
ベストプラクティス集
データ処理の仕組みで最も苦労するポイントの1つが次のような元データの不整です。
- 日付列に文字列が入るなどのデータ型のエラー
- 複数データで列名が一致しない
- 空白行が入り込みデータが途切れる
これらのエラーを極力回避するためのベストプラクティスは以下のようなものがあります。
- テーブル書式を活用
- データ規則を適用する
- 記入用のテンプレートを作成・活用
- エラー処理を入れる
順に解説します。
テーブル書式を活用
Excel には「テーブルとして書式設定」というボタンがあります。これを活用すると次のようなメリットがあります。
- データの範囲が明確になる
- 列名の欠落や重複を自動的に回避
- 関数式を入力すると自動で全行に適用(式の入力漏れを回避)
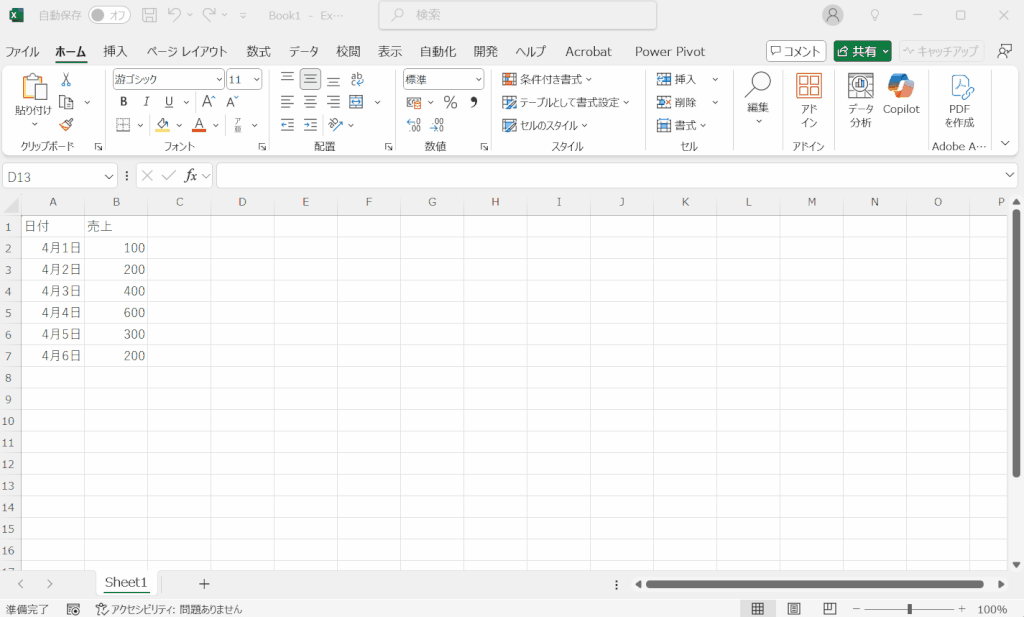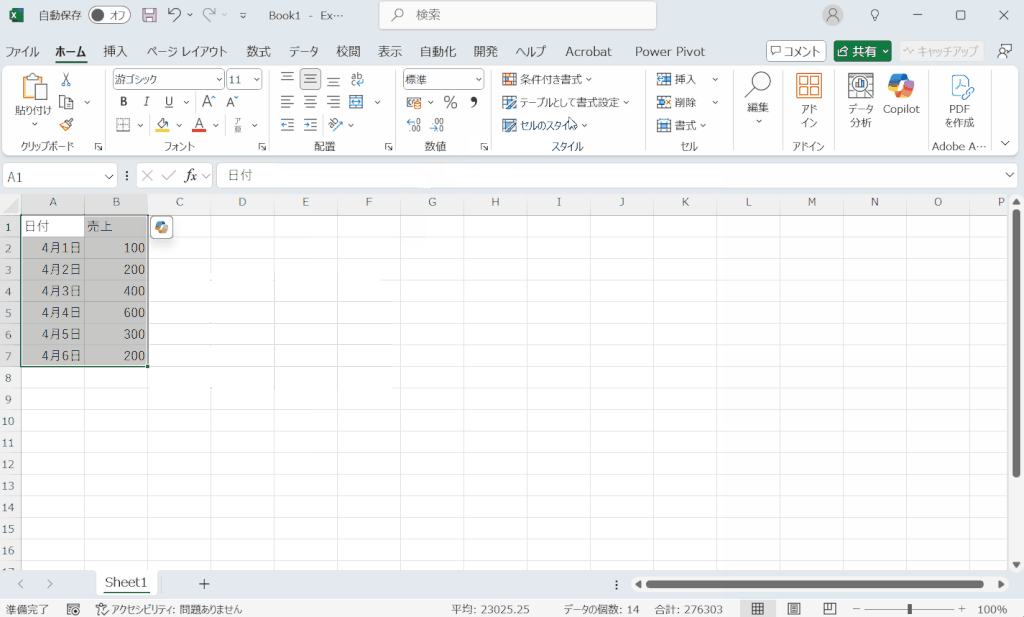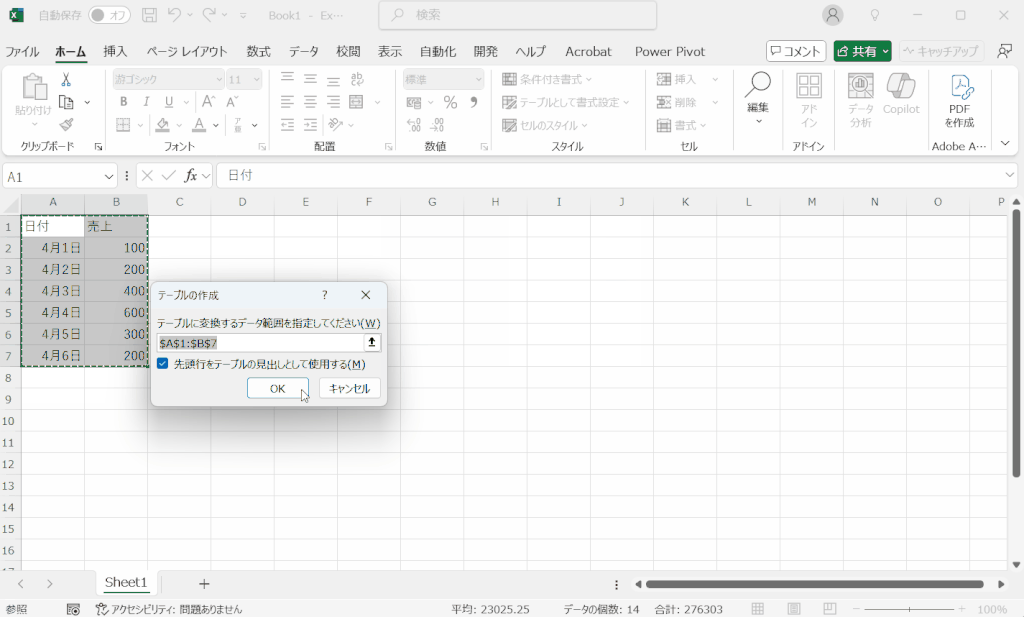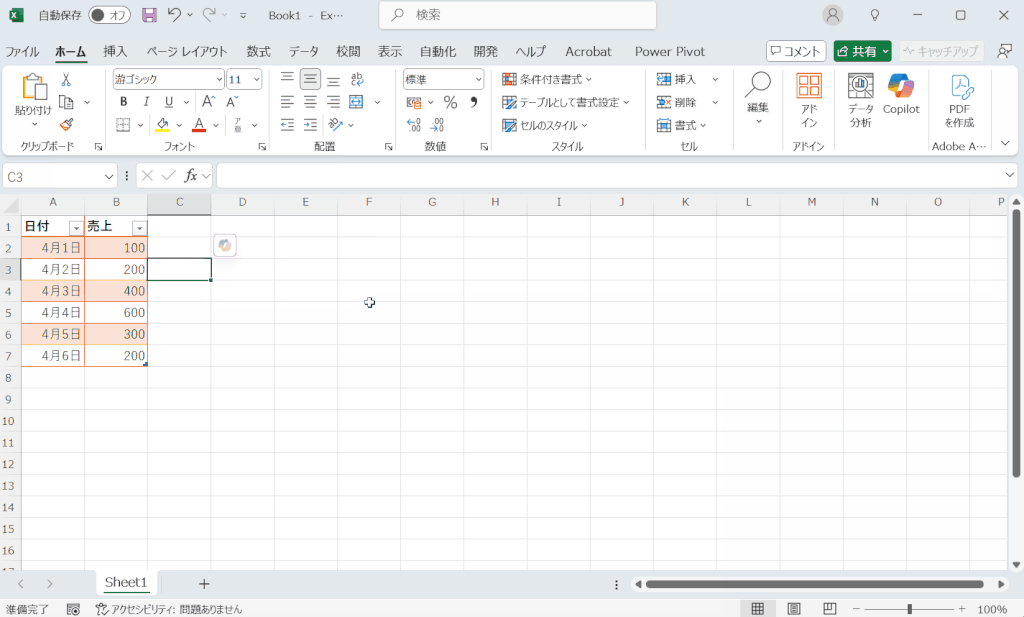
テーブル書式の設定方法
データを入力したセルにテーブル書式を設定するには下の動画のように操作します。
テーブル書式の活用については、以下の記事でも詳しく紹介していますので、よろしければご参照下さい。

データ規則を適用する
Power Query で発生するエラーの主な原因の一つがデータの型の不整合です。数値が入るべき列に文字列などが入っているとエラーで処理が止まってしまうことがあります。
これを防止するために、データ列に入力する値に制限をかけます。
下の図のように操作して データの入力規則 のウィンドウを出します。

- 列の項目の上にマウスを移動させるとポインタが 下矢印 に変わるのでそこでクリックして 列を選択 します
- メニューから データ をクリック
- リボンメニューから データの入力規則 をクリック
- 入力値の種類 からその列で設定するデータの型を指定します
この設定をしておくと、例えば 日付 の列に 「未定」 などと文字列を入力するとエラーになって入力が中断されるようになります。
記入用のテンプレートを作成・活用
複数の人にデータの提供を依頼する場合は、依頼する前にテンプレートを作成するのがベストプラクティスです。
前述のように表を作成して、Excel のテーブル書式を適用、更に データの入力規則も適用 することで、提供されるデータが最初からかなり整ったものにすることが可能です。
エラー処理を入れる
データを読み取るテーブルに関数式が入っている場合、時々セルの値が #DIV/0! , #NULL! , #REF! などのエラーになってしまうことがあります。
セルの値がエラーになっていると Power Query の処理が止まる確率が非常に高いです。これも回避が必要です。
例えば「売上」という数値データの列の場合、図のようにして数値変換とエラー処理を行います。

- Power Query エディターのメニューから「列の追加」>「カスタム列」をクリック
- 出てきた「カスタム列」のウィンドウに以下の M関数式 を入力
入力する「カスタム列の式」
= try Number.From([売上]) otherwise 0解説
ここでM関数式の try [処理] otherwise [値]構文 を使用しています。これは以下のように動作します。
- [処理]を実行します
- [処理]が エラー無く 実行できればその 処理結果 を出力します
- [処理]が エラー になってしまった場合、その代わり(otherwise) に [値]を出力 します
このように、 try [処理] otherwise [値]構文 はエラーで処理が止まるのを回避する機能があります。
ここでは[処理]の内容が Number.From([売上]) となっています。
直訳すると、数値を~から という意味で、「売上」列のデータから数値を出力する処理になります。
元々数値を入れるはずの「売上」列ですが、例えば「未定」とか「調整中」などの文字列が入力されているた場合、Power Query の処理の途中でエラーになってしまいます。
これを回避するために try [処理] otherwise [値]構文 でエラー処理を加えた訳です。
この後で、元の「売上」列は削除して、「売上2」を「売上」に名前を変更しておきます。
これで「売上」列はエラーの無い整ったデータ列にすることが可能です。
クエリの再利用性を高める設計
Power Query でのデータ処理は、データ型の設定、文字列加工、計算処理、テーブル結合など様々な処理があります。
これらのデータ処理全体を効率的に管理するにはどうしたら良いのでしょうか?
クエリの作成のベストプラクティスというものがあります。それは次のようになります。
- Step1 まず最初にデータを整えるクエリを作成
- Step2 1. のクエリを参照してデータを加工 するクエリを作成
- Step3 2. のクエリをテーブル結合してデータ処理用のクエリを作成
この順番でクエリを分けて作成することで、例えば Step2 で Step1 のクエリを複数回再利用することができます。
Step1 できれいにデータが整っていることで、Step2 ではデータ不整の心配をすること無く、データ加工に集中することができます。
同様に Step2 で利用価値の高いデータを整えておくことで、Step3 でデータを様々に組み合わせてデータ出力用のデータを作成することが可能になります。
これを図で解説すると次のようになります。

クエリの整理方法については次の記事でも詳しく解説していますので、よろしければ参照してみて下さい。

ピボット解除は最初に実行
図のようなデータファイルがフォルダ内にある場合は、ピボット解除を一番最初に実行するのがベストプラクティスです。

「年月」の列は時間が経過すると変更が必要になります。例えば1ヶ月経てばその1ヶ月分の列は不要になるなどです。
しかし、Power Query で読み込むデータ列を固定してしまうと、列が変更された途端にエラーになってしまいます。
これをサンプルファイルのクエリで 個々のファイルを読み込んだ直後にピボット解除 することで、列名の変動に対応できる ようになります。
というのも、ファイルを読み込んだ直後に固定列以外の列を列名を確認することなくピボット解除してしまうからです。
自動のデータ型指定は削除しておく
Power Query は通常、ファイルを読み込んだ直後に列のデータ型を自動で設定します。
しかし、このケースのように列名がファイルごとに変化する場合、このデータ型の設定は「列が存在しない」というエラーになってしまいます。
ピボット解除してしまえば変化する列名は無くなりますので、最初のデータ型の設定処理は削除して、後でデータ型の設定を行います。
まとめ
Power Query は業務の自動化に大きく貢献します。中でもフォルダの読み込み機能は大量のデータファイルを次々と処理をしてくれるので非常に有益な機能です。
この記事ではフォルダ読み込みの基本操作と様々な応用方法を解説しました。この方法を活用すれば皆さんが抱えている定期的なデータ処理の悩みを一気に解決できるかもしれません。
是非この Power Query のフォルダ読み込み機能を少しずつでも自分の業務に取り込んでみて下さい。その便利さをより実感できると思います。
このサイトでは仕事の効率化に大いに役立つ Power Query の活用法などを紹介していますので、他の記事も興味があれば参照してみて下さい。

